What is Information Architecture?

Information architecture (IA) is the practice of organizing, structuring, and labeling information to make it easier to find and understand.
For example, consider the choices in a website’s navigation menu. They represent groups of related information. If they make sense, you’ll quickly find what you need. Conversely, if information isn’t organized logically, you’ll grow frustrated and leave.
Benefits of Information Architecture
Knowing how to organize information can help you personally. But IA is essential for product design — especially for complex products or those that offer lots of information. There are many ways IA benefits organizations:
- Improved User Experience (UX): Good information architecture allows users to navigate your website or app effortlessly, increasing user satisfaction and engagement.
- Increased Findability: A well-structured information architecture ensures content and features are easy to find and access, benefiting users and improving SEO.
- Scalability: Good information architecture allows digital systems to adapt to change, avoiding potential confusion as new features and content are added.
You know IA works when people find systems easy to use: they easily find what they’re looking for and get stuff done.
An Information Architecture Process
Effective information architecture doesn’t emerge organically; it must be designed. But that doesn’t mean the process is entirely top-down. At each stage, there are opportunities to validate directions and correct course.
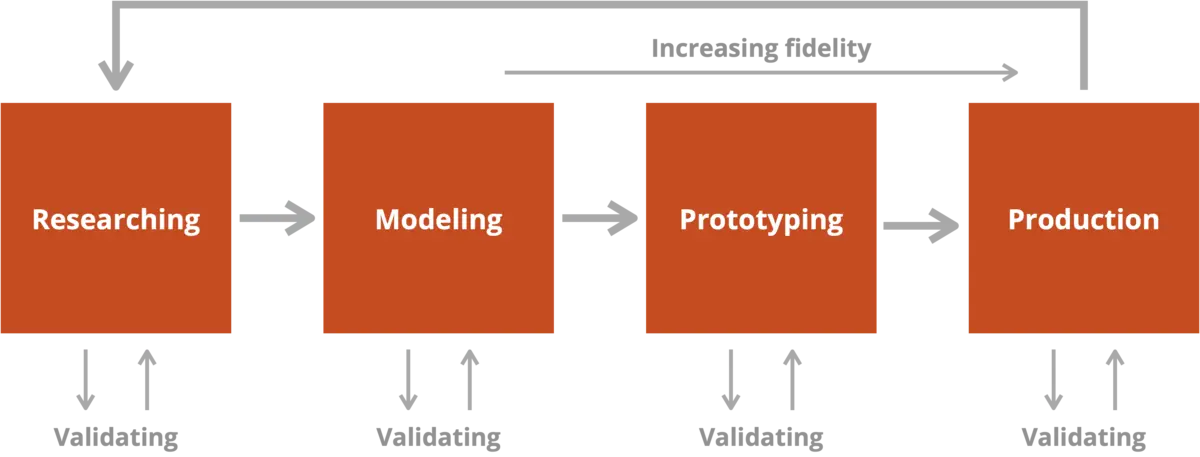
Broadly speaking, the process has four sequential steps:
- Researching
- Modeling
- Prototyping
- Production
Let’s look at each step in more detail.
Information Architecture Research
Organizing information so it makes sense is easier said than done. For one thing, different people understand things differently. For another, some content will be unfamiliar: people don’t know how to think about it.
Because of this, designing effective information architectures starts with research. In particular, we want to learn about three areas:
- Content: Concepts the system must present to users so they can accomplish their tasks.
- Users: The mental models and conceptual understanding of the system’s intended audiences.
- Context: The environment surrounding the project, including motivations, competitors, regulations, infrastructure, etc.
Learning about user mental models is particularly tricky. Card sorts are a useful research method that allows you to uncover how people group particular sets of information.

Modeling
After understanding the project domain, the next step is developing models to explore how the system might be organized.
Models are diagrams that include key concepts and the relationships between them. Models allow teams to see the system’s “big picture,” including terminology and hierarchies.
Common models include:
- Concept models, which explore the overall structure of the system,
- Content models, which explore the attributes used to describe those concepts and the relationships between them, and
- Sitemaps, or tree diagrams, which describe the relationship of screens or pages in the system.
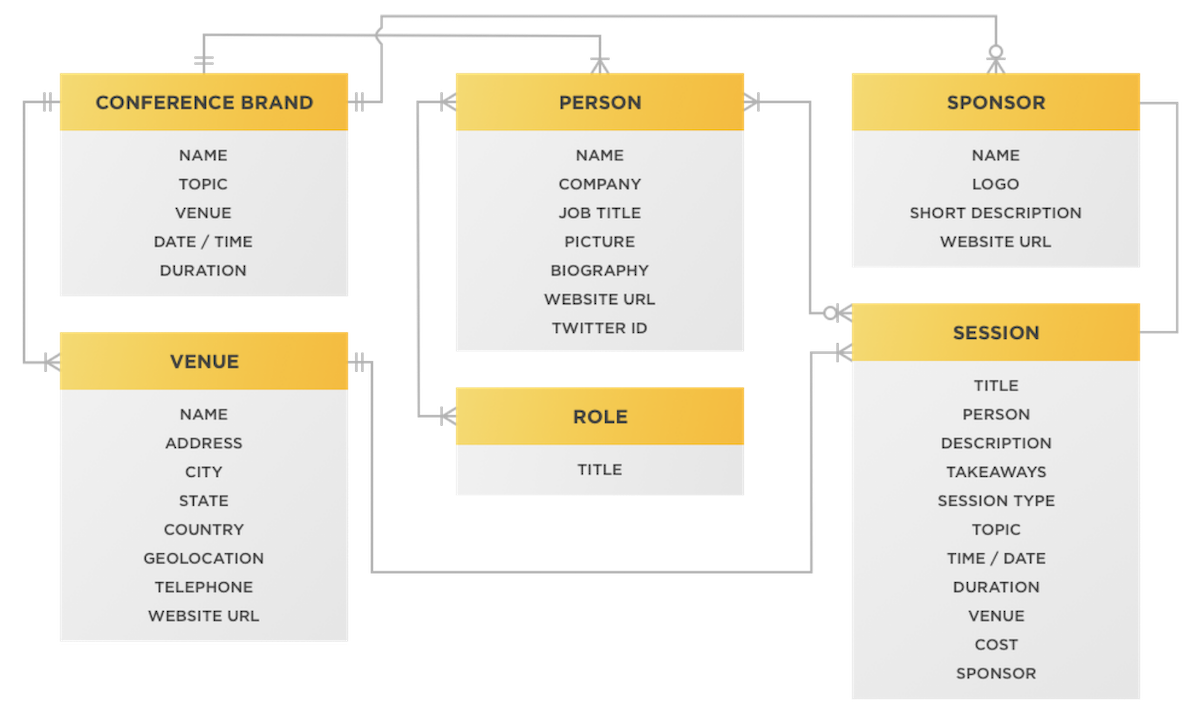
Sitemaps, in particular, are closely associated with information architecture. They have their uses, but keep in mind that most interactive systems aren’t strictly hierarchical.
During the modeling stage, you can validate directions by conducting Tree Tests, which allow you to test and refine proposed groupings and labels.
What’s With the Polar Bears?
Louis Rosenfeld and Peter Morville published Information Architecture for the World Wide Web in 1998. As with other O’Reilly books, this one featured an animal on the cover — in this case, a polar bear.
IA for the WWW quickly became the definitive book for people designing IA for complex websites. Perhaps because of its long title, practitioners started referring to it as the “polar bear book.” Polar bears have been the unofficial mascot of information architecture since then.

The definitive guide to IA — for the web and beyond.