
Back in november, I shared an approach for using AI to alleviate a common chore in information architecture work: re-categorizing a large set of content. That post was a proof-of-concept: it stopped short of actually doing the work. Now I’ve actually done it, and this post explains the approach in practice, warts and all.
First, a refresher of what I aimed to do. My blog is built using Jekyll and contains almost 1,200 posts spanning almost twenty years. I wanted to improve the discoverablity of older content and decided on a technique that finds possibly related posts at build time by identifying posts that share at least two tags.
In practice, this approach only works well if each post has at least three tags. The problem is I haven’t consistently tagged posts; some older posts had only one tag and a few had no tags at all. (Cobbler’s children, etc.) Additionally, the taxonomy evolved over time so some older content wasn’t tagged meaningfully.
Re-tagging everything would entail re-reading (or at least skimming) each post and applying at least three tags from the current taxonomy. If we assume five minutes per post, we’re talking around ten hours of mind-numbing work. I couldn’t justify it.
But this work is perfect for robots. Large language models excel at spotting patterns in text. That’s the proof-of-concept I outlined earlier: it used Simon Willison’s open source llm command line tool to invoke GPT-4 via OpenAI’s API. The prompt asked the model to categorize each post according to a pre-set list of terms. (The tag taxonomy.) Do this for each post, et voilá, you’ve re-categorized the whole site.
That was the theory, anyway. Now let’s look at how the process worked in practice.
Step 1: Preparing the Taxonomy
Before having the LLM process the site, I needed to update the tag taxonomy. Some terms were somewhat generic and widely-understood (e.g., ‘Process’, ‘Design’, ‘Language’), but others were highly idiosyncratic.
For example, some posts were tagged ‘TAOI’, an acronym that stands for “The Architecture of Information.” It’s a phrase I used for a while to identify in-the-wild examples of things and environments that somehow reflected information architecture wins or fails. Hard to explain to humans — and hard to get GPT-4 to tag posts with this term.
So I killed it. Instead, I used ‘Information Architecture’; a more recognizable term. I also changed ‘UX’ to ‘User Experience’, ‘UI’ to ‘User Interface’, and ‘Extended Mind’ to ‘Cognition’ — all in service to making it easier for the LLM.
Takeaway: LLMs tend to have a middlebrow ‘understanding’; they don’t deal well with idiosyncrasies. When prompting LLMs, stick with widely understood terminology. (I’m exploring RAG as a way to overcome this issue.) But it’s worth considering that if the terms are hard for the AIs to work with, users might find them difficult as well.
Step 2: Previewing All Changes
With a cleaned up taxonomy, I was ready to let the LLM process my content. The approach here is the same I outlined in november; the only change is that GPT now has a longer context window so I no longer needed to truncate posts at 4,000 tokens.
Again, the idea was to have the LLM look at each post in the site and tag it with three terms from a predefined list. As noted in the previous post, I planned to use the yq command line tool to insert the new tags directly into the Markdown file’s YAML.
Given that the content is stored as plain text in my filesystem, the easiest way to do this is with a shell script. But knowing LLMs’ propensity to make stuff up, I wanted to preview changes before modifying the Markdown files directly.
I decided to implement an intermediary step: rather than modify posts directly, the script would generate a CSV file that I could open in Excel to compare each post’s existing tags with the ones proposed by the LLM. Here’s the script:
#!/bin/zsh
# Set post directory
DIR='/Users/jarango/Sites/dev.jarango.com/_posts'
# Start a new CSV file in the current directory
echo "File,Title,Categories,Tags_Old,Tags_New" > ./post-metadata.csv
# Begin loop that looks through each file in the post directory
for FILE in `ls $DIR/*.md`;
# use yq to extract its title and current (old) tags
do TITLE=$(yq --front-matter=extract '.title' "$FILE" -o=csv);
CATEGORIES=$(yq --front-matter=extract '.categories' "$FILE" -o=csv);
OLDTAGS=$(yq --front-matter=extract '.tags' "$FILE" -o=csv);
# use llm to 'read' the post and select three tags from the taxonomy
NEWTAGS=$(cat $FILE | llm -s "Pick the three tags from the following
list that best describe the content of this post. Only select tags from
this list; do not introduce any new ones or edit the ones currently in
the list. Present the results separated by commas with no spaces between
them. These are the possible tags: Apple, Artificial Intelligence,
Books, Business, Career, Cognition, Design, Distinctions, Ethics,
Events, Information Architecture, Interaction Design, Interviews,
Language, Leadership, Links, Management, Mapping, Media, Meta, Modeling,
Newsletter, Personal, Personal Growth, Placemaking, Platforms, Podcast,
Presentations, Principles, Process, Product, Productivity, Publishing,
Quotes, Research, Society, Software, Strategy, Systems, Teaching,
Technology, Tools, User Experience, User Interface, Values, Videos,
Workshops" -m 4t);
# write a new line to the csv file
echo -n "$FILE,\"$TITLE\",\"$CATEGORIES\",\"$OLDTAGS\",\"$NEWTAGS\"\n" \
>> ./post-metadata.csv;
# End loop
done
The magic sauce is obviously the prompt, including the taxonomy of tags. Note I’ve explicitly asked GPT to limit itself to just these tags and to not introduce any new ones. (I’m calling this out in service to the time-tested writing technique known as ‘foreshadowing.’)
In any case, the script took 47 minutes to go through all 1,162 posts in the directory. This is what the CSV file looks like when opened in Excel:
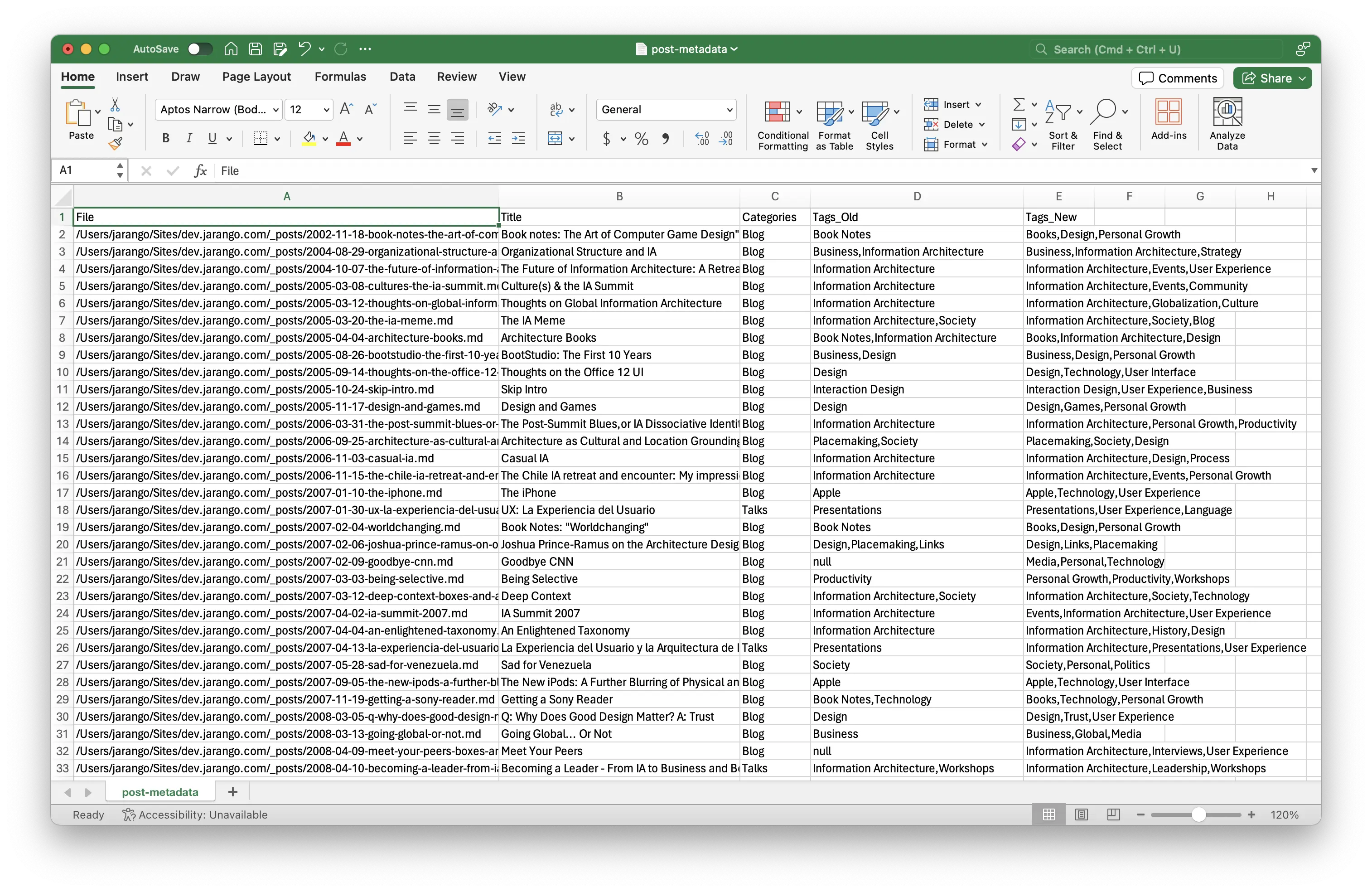
The spreadsheet has four columns:
- File: the location of the Markdown file in my computer
- Title: the contents of the title attribute in the file’s YAML header
- Category: the contents of the category attribute in the file’s YAML header
- Tags_Old: the contents of the current tags in the file’s YAML header
- Tags_New: the new tags proposed by GPT
A few observations:
- Some posts don’t currently have any tags; they’re labeled ‘null’
- Jekyll has the concept of categories in addition to tags; I’ll likely develop this further in the future, but won’t deal with it here
- Tags are separated by commas
That last point is a doozy, since CSV files are delimited with commas. The way I dealt with this is by wrapping all data entries in quotes. This is problematic, since some titles include quotes. If I were building a production system, I’d have to deal with these issues; as it stands, this is more of a hack.
But it worked. After less than an hour, I had a good first pass at draft tags for all posts in the site.
Not all was okay, though. As I reviewed the spreadsheet, I noticed several posts tagged ‘AI’ and ‘UX’, among others. These terms were NOT in the taxonomy I passed to the LLM; clearly the model had overridden my request. I used find-and-replace in BBEdit to clean these up in preparation for the third step: applying tags to the posts themselves.
Step 3: Tagging Site Posts
At this point, I had a CSV file with proposed tags for each post in the site. Now, I needed to iterate through each post in the site applying the new tags. Again, the easiest way for me to do this kind of thing is with a shell script.
I could’ve written this script to read each line in the CSV file and modify the post named in the File column. But rather than have the CSV call the shots, I decided to have the script read the name of each file in the directory and search for that line in the CSV file. The CSV basically functions as a database I can query to run one-off changes on particular post files. This is a more flexible approach, if a bit slower.
When I say “basically functions as a database”, I mean it literally: the script uses a command line tool called csvsql to run a SQL statement on the CSV file. This statement returns the contents of the Tags_New column for the row that matches the file name for each post in the directory. The script then writes those new tags to each post file using yq. Here’s the script:
#!/bin/zsh
# Set directory
DIR='/Users/jarango/Sites/dev.jarango.com/_posts'
# Begin loop that looks through each file in the post directory
for FILE in `ls $DIR/*.md`;
# Find the content of Tags_New for the row that matches each file name
# and modify the output to proper CSV (with quotes)
do NEWTAGS=$(csvsql --query \
"SELECT Tags_New FROM 'post-metadata' WHERE File='$FILE'" \
./post-metadata.csv | sed -n '2p' | sed -r 's/,/","/g');
# Add the new tags to each post file
yq --front-matter=process -i 'del(.tags) | .tags += ['$NEWTAGS']' $FILE;
# End loop
done
Caveat: If you decide to try this, BACK UP YOUR DATA FIRST. This script will change post files directly. It’s what you want when dealing with ~1,200 files, but if something goes wrong and you have no backups, you will be sad.
Running the script took around 15 minutes. At the end, it had properly re-tagged all posts in the site. Well, ‘properly’ overstates the case — more on that below. For now, I’ll just say it behaved as expected.
Step 4: Cleaning Up
After running the re-tagging script, I opened a few posts using BBEdit. All looked well, so I had Jekyll rebuild the site. The related posts feature worked as expected. Big win! But all wasn’t well. When I reviewed the site’s Archive page, which lists all tags, I discovered some tags that weren’t in my taxonomy.
Some of these were dumb mistakes. For example, there was both a Books tag and a Book tag. Clearly GPT had introduced its own terms into the taxonomy. If I had a bit more time, I’d tweak the prompt to ensure better compliance. That said, some of the terms it added improved my taxonomy. For example, the LLM introduced a History tag that wasn’t in the original list. I decided to keep some of these terms.
But these new tags only considered individual posts; the LLM had no sense of the entire corpus. As a result, most of these new tags only applied to one or two posts; not useful for this project’s purpose. A better approach would have the LLM take a second pass at the taxonomy while looking at the whole site, perhaps through summarization.
Tweaking the implemented taxonomy (using BBEdit’s fabulous global search-and-replace feature) took around an hour. In the end, I had a good list of tags and a “See also” feature that adds value to the site.
Final thoughts
If you add up the time it took to run the scripts and clean up the results, the process took a bit under three hours. Obviously, I wasn’t involved during part of it. (I did a grocery run while GPT re-tagged the site!) Compared to the 10-hours plus it would’ve taken me to do this manually, it was a huge time savings.
Of course, writing and debugging the scripts took considerably more than three hours. But this was an important learning experience, and I expect to re-use these techniques (if not these exact scripts) in other projects.
So I consider this experiment a success. This approach can greatly reduce the cost and time-to-market of large re-categorization projects. While this particular case uses command line tools to modify local files, there’s no reason why these techniques couldn’t be used to re-categorize content in other CMSs that expose APIs.
I remain in awe of generative AI. Even if LLMs aren’t sentient (spoiler: they aren’t), they offer unprecedented capabilities for processing large sets of content. The trick is to use them for the things they do best. This project is an example, but there’s more to come. Exciting times!