
Update: check out the newer Agent Skill version of this tool.
Starting last year, I’ve been running experiments to see how LLMs might help with my work. The most obvious use case for information architecture is organizing information, so the first couple of experiments leaned in that direction. Here, I’ll share a third experiment that might be useful earlier in the IA process.
In particular, I’m looking to aid research. When starting a project, I aim to understand the system’s content, context, and users. Some of this entails interviewing users and stakeholders, but much of it is desk research: learning about the product, its subject matter, competitors, etc. by reading web pages, PDFs, presentation decks, and videos.
As a visual thinker, I often reflect on what I learn in concept maps. These visualizations serve as a shorthand to communicate models about the domain. I show maps to subject matter experts, stakeholders, and clients to align our understanding of what we’re working on. Their feedback leads to more accurate maps (and therefore, more accurate models.)
Given how quickly concept maps help teams get aligned on their understanding, I thought it might be useful to develop a tool to expedite the creation of concept maps. I don’t mean a tool to help you draw a map. After all, there are great diagramming tools in the market. I mean a tool that will draw concept maps for you.
Synthesis is one thing LLMs do well. Ask ChatGPT to summarize an article, and you’ll get a useful couple of paragraphs that get to the gist of whatever you’re wanting to understand. But the output is still text. What if it could do the same but render a diagram instead?
So that’s what I’ve been working on: an AI-assisted concept mapping tool. I call it LLMapper. In its current incarnation, it “reads” the contents of a web page and spits out a concept map, like this:
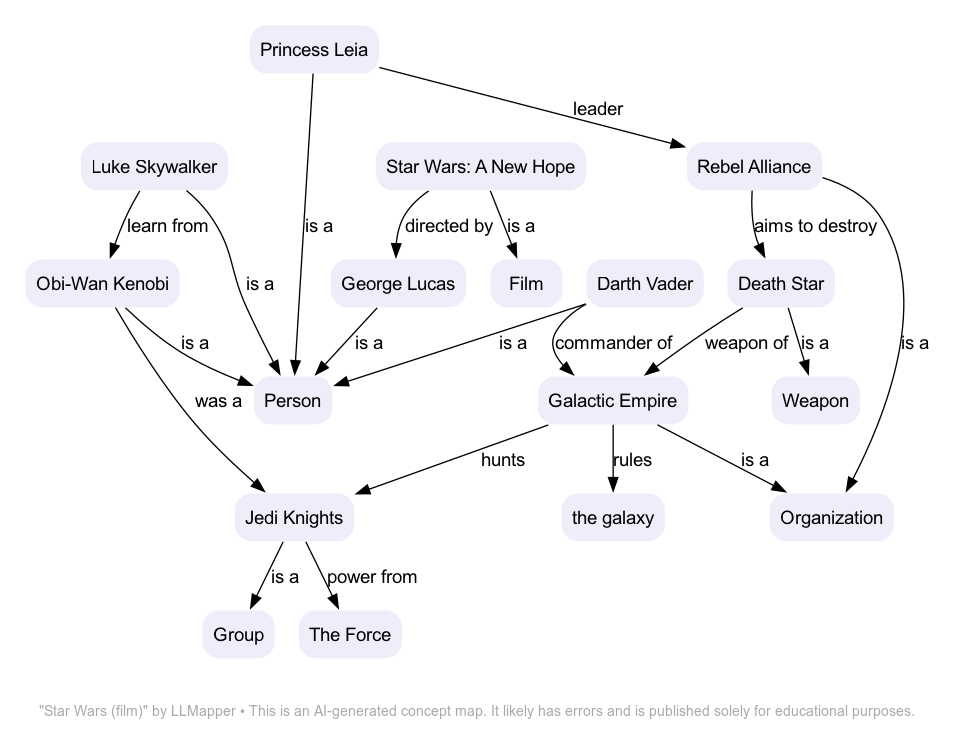
This is a concept map of the Wikipedia page of the first Star Wars movie. To get this result, all I needed to do was go to my Mac’s command line and pass the URL for this web page to the correct Wikipedia page, like this:
./llmapper https://en.wikipedia.org/wiki/Star_Wars_\(film\)
Currently, the tool has several limitations. For one thing, it’s hardwired to only read Wikipedia pages. That should be easy to fix. (It could parse any text at all; it doesn’t need to be a web page.) It also has no error checking; you could pass it garbage and it would try to work with it. That, too, should be fixable, but I’ve focused my explorations elsewhere.
And that’s okay since this isn’t meant as a production tool. It’s a way to learn about AI. The best way to learn about a new technology is to do stuff with it. (Far too many people are developing passionate opinions about AI without venturing further than ChatGTP. This is a mistake.)
But there might be a practical outcomes here beyond learning about AI. For visual thinkers, concept maps help elucidate complex subjects. It’s a skill I teach students of my systems course, and one that all systems-oriented designers should acquire. Having a concept mapping assistant could expedite the research stage of UX design projects.
How It Works
Currently, LLMapper is a shell script that cobbles together a bunch of other command-line tools:
The key tool here is Simon Willison’s llm. I’ve written about this tool before since it’s at the heart of my other experiments with AI. Willison describes it as a “[command-line interface] utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your machine.”
That means that it allows you to pass and receive information from a command-line interface (such as the one you access via your Mac’s Terminal app) to and from large language models. I’m using GPT-4, but llm allows you to use other models as well, including local open-source models.
By “passing and receiving” information, I mean you’re liberated from the constraints of the chat-based interface. Much of what you do with computers can be reduced to text. At that point, you can use the CLI to manipulate it in various ways. llm lets you add AI smarts to that ecosystem.
LLMapper uses llm to parse text from a particular section of a web page (i.e., a named DIV) and pass that to GPT-4 in three separate calls, each of which transforms it in particular ways:
- The first call summarizes the article and extracts its key concepts and relationships.
- The second call renders those concepts and relationships as an RDF-formatted knowledge graph.
- The third call transforms the RDF code into DOT code that Graphviz can render as a concept map.
There are a few other bells and whistles, but that’s the gist of it. Each “call” is a prompt that instructs GPT-4 to do various things, such as summarizing text, converting it to RDF, and converting it to DOT. Most of my “coding” time on this project has consisted of tweaking these prompts to get them to produce relatively reliable results.
Issues and Lessons Learned
I say “relatively” because the tool still has a lot of issues. The third step is reliable: GPT-4 is good at transforming RDF code into DOT code. But steps 1 and 2 are highly variable. Sometimes, the results are impressive, but often, they’re crap. ‘Scattered’ maps — those with no central focus — are a common problem. This is an example from the same web page as above:
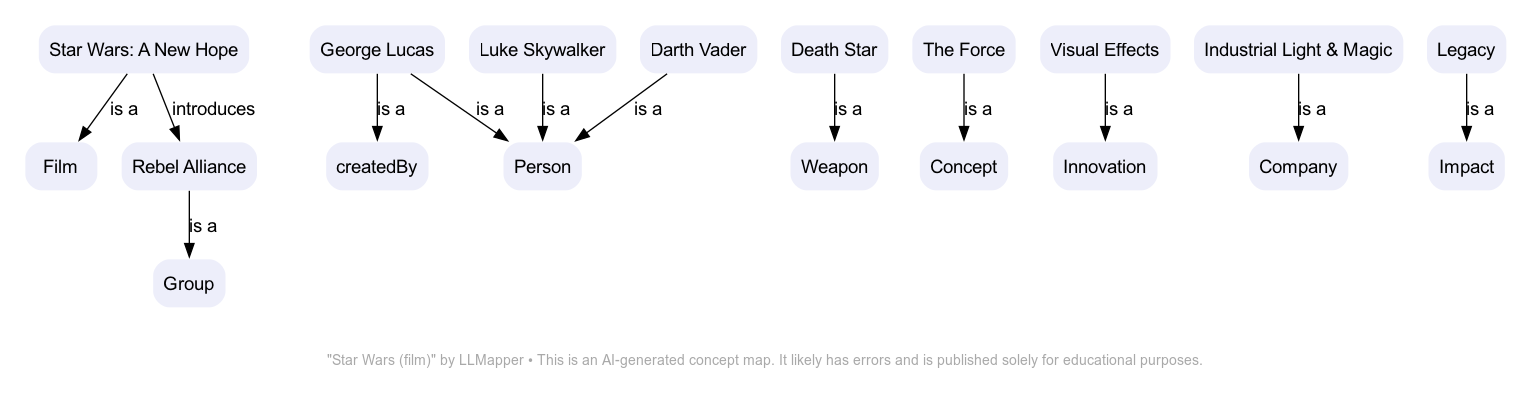
Another common issue I’ve struggled with is relevance. Some LLMapper diagrams include lots of irrelevant details but miss the important stuff. This issue primarily affects step 1. I’ve noticed some Wikipedia pages produce better results than others. The problem compounds down the line: if the summarization and concept extraction step goes wrong, the RDF and DOT transformations will be wrong too. Garbage in, garbage out.
A realization I’ve had in working with this and other LLM-based tools is that claims about these tools having emergent intelligence are over-optimistic. LLMs really are super-powerful forms of autocomplete — and not much more. LLMapper makes mistakes that no human would. These systems don’t seem to have underlying models of the world — just predictions of what word is likely to come next in a sequence.
That turns out to be incredibly useful in a variety of scenarios. We have only caught small glimpses of these things’ capabilities. LLMs have already forever transformed how many knowledge workers — including me — create value. That said, I have a hard time seeing how they lead to artificial general intelligence.
But the main lesson I’ve learned while working with LLMapper is that rather than thinking of an LLM as some kind of omniscient superintelligence, it may be more useful to think of creating discrete ‘intelligences’ (or small agents) that collaborate with each other towards achieving a specific outcome. In this case, the three prompts require three kinds of ‘thinking’:
- Summarizing
- Encoding in a knowledge graph
- Translating the knowledge graph to a diagram
These are distinct processes. By breaking them up, I can develop them independently. Like I said, I feel good about step 3, but steps 1 and 2 can clearly be better. The RDF step is particularly primitive. (I’m learning about knowledge graphs as part of this project.) There are other projects that aim to process knowledge graphs with LLMs, and those could clearly help here.
Breaking free of the chat UI has been a boon. By using llm, I can pipe the output of one prompt into another, essentially allowing these little ‘agents’ to work with each other. There are many other problems beyond concept mapping where this approach could prove useful. If I get nothing else out of this experiment, this modular way of interacting with LLMs is something I’ll definitely use in other projects.
Try It Yourself
If you want to see more results from LLMapper, I’ve started a website called Modelor.ai to share outcomes from these experiments. It’s a running journal where I document tweaks to the tool and its prompts. Again, the point is learning how to work effectively with LLMs. Sharing the stumbles and successes is part of the process.
You can download LLMapper from Github; it’s published under an Apache license. As I mentioned above, this is a learning toy and not a production tool; it has nothing but rough edges. It assumes you have some command-line chops and has only been tested on Macs. (It should be easy to install on Linux systems. I’m not familiar enough with Windows to know what needs to happen there.)
If you do use it, I’d love to hear how you’re playing with it. I’m excited by the possibilities of LLMs and want to learn more. I’ve already learned a lot from the few folks who’ve used this tool. I’d love to hear from your efforts if you do decide to try it.