This post is part of the series in which I share aspects of my personal information ecosystem. Read all the posts.
Most of my work centers around ideas. Whether it’s an article I’m writing or research for a design project, I’m always learning new stuff. I collect and nurture ideas in an information garden. (Other folks use the term digital garden, but I’m not keen on this usage, since my garden isn’t exclusively digital.)
My garden has two central components:
- Places to store and process information. Includes links to web pages I’ve read (or need to read), PDFs from academic papers, books, audio/video files, etc.
- Places to write. Includes notes to self, meeting minutes, outlines, blog posts, etc.
Much of this happens in software, but not all. For example, physical books are an important part of my information store. I also write and sketch a lot in paper notebooks. But ultimately, everything gets digitized. Currently, I use DEVONthink as my primary storage/processing application, and Obsidian for taking notes.
It’s a great combination because each app has strengths the other lacks, but both support Markdown text, so they can interoperate. (My setup has been influenced by what I’ve seen other people doing — especially Andy Polaine and Kourosh Dini.)
Obsidian is a hypertext note-taking application. There are a few similar applications in the market (most notably, Roam), but Obsidian’s key differentiator is that it stores notes in plaintext Markdown files in your computer’s filesystem (as opposed to a cloud-based server.)
DEVONthink is an “everything bucket” application that allows you to save bookmarks, PDFs, images, and much else into databases where you can organize information in ways that suit you. As with Obsidian, DEVONthink runs and stores its data locally in your computer. (Of course, you can also sync this data over iCloud and such.)
DEVONthink’s killer feature is its use of AI to spot relationships you may have missed between items in the database. For example, you might be examining a blog post and realize there’s a PDF for an academic paper in your database that delves deeper into the same issue. This is a powerful capability, especially if you’ve been collecting information for a long time.
Another key DEVONthink feature — and the one that enables its interoperation with Obsidian — is its ability to index and manipulate items in folders in the computer’s filesystem. In other words, DEVONthink can work with files that reside outside its database.
As you might have guessed, this can include Obsidian’s “vault.” (The folder where it keeps your notes.) Since both applications understand Markdown, you can view (and edit) your Obsidian notes using DEVONthink. (Kourosh published a post that explains how to set up this integration.)
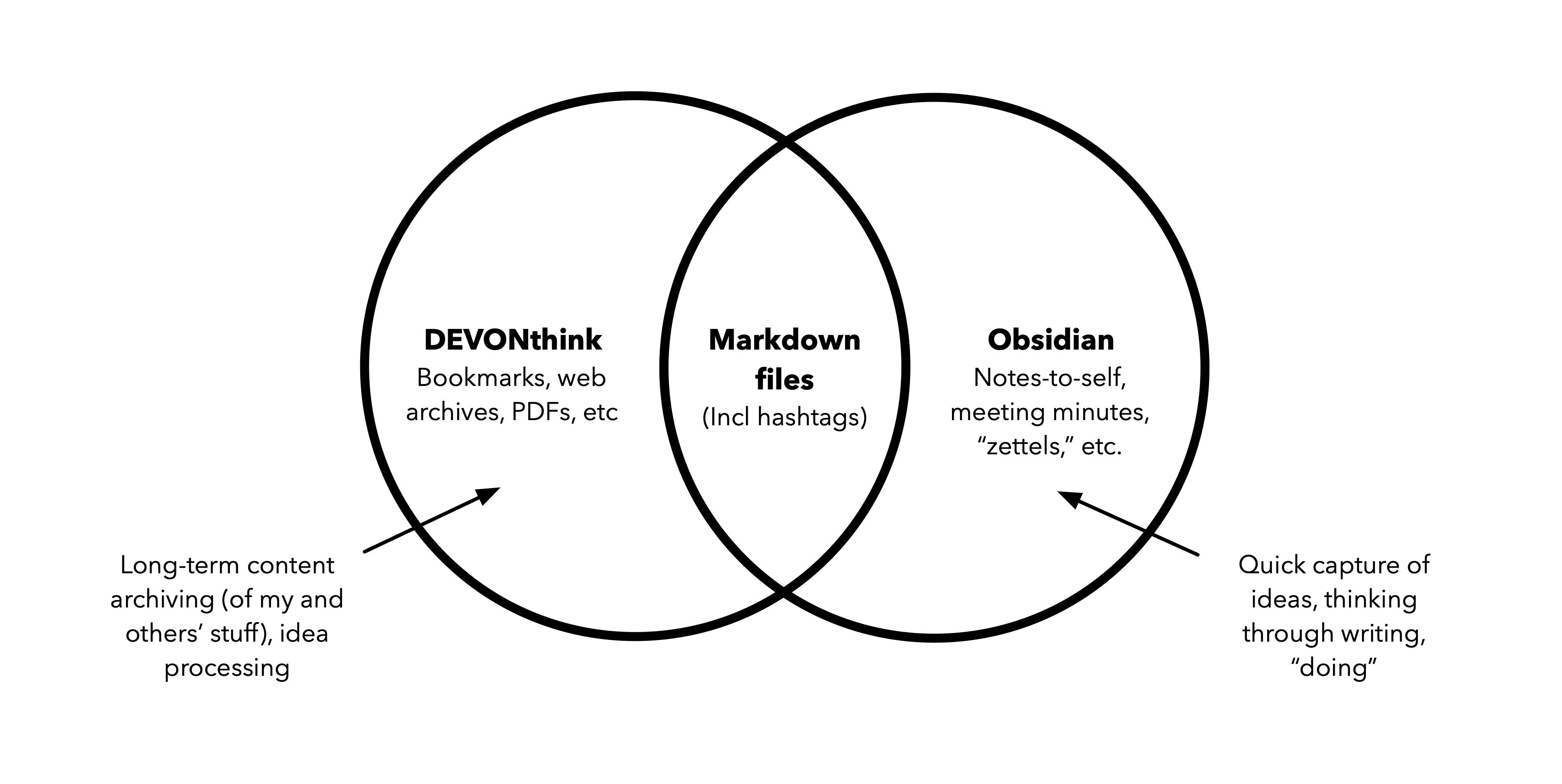
An overview of the core of my current information garden.
This is a “best of both worlds” situation: while Obsidian is great for writing and making (explicit) connections with other notes, DEVONthink is great at finding unexpected connections between those notes and other items, including web pages, PDFs, passages from books, etc. It’s a powerful combination.
My setup is a work in progress. Before using Obsidian, I took notes in DEVONthink itself. Recently, I’ve moved most of those notes to Obsidian. So, I’m drawing clearer lines between both apps: Obsidian is for capturing my thoughts, while DEVONthink is for archiving and processing items I’ve encountered elsewhere.
I’m finding that as both data stores grow, “weeds” sprout in the garden. An example is unintentional tags.
Tags are an important DEVONthink feature. You use them to automatically organize and process information. You can tag items manually, but that’s not the only way things get tagged. For one thing, DEVONthink can automatically turn words preceded with a hash (#) into tags. So if you import a file that contains #open in its text, the file will be assigned the open tag in DEVONthink. (This feature is optional, but I’ve enabled it, since it allows for easier automation and integration with other systems.)
Obsidian also understands #hashwords as tags. Obsidian’s tagging system is different from DEVONthink’s, but you can include tags in Obsidian notes and have DEVONthink assign the same tag in its database. Again, super powerful integration.
But there’s a downside: Obsidian doesn’t know about DEVONthink’s tags database, so you’re not using its tag collection when taking notes. If you inadvertently mistype a tag in Obsidian, DEVONthink will create a new tag with the typo.
And that’s not the only way in which new — and potentially mangled — tags make it into DEVONthink. Here are some others:
- I’ve seen the app interpret hex color codes (which start with a hash) in certain documents as tags.
- DEVONthink allows you to subscribe to RSS feeds, and I follow my blog so that posts go automatically into my repository. The app is smart enough to import my post’s WordPress tags into its collection.
- I imported my old bookmarks from Pinboard, and DEVONthink merged the tags from that system into my local database.
I’m sure there are more, since DEVONthink is very flexible — these are just ones I’ve experienced. That’s a lot of ways to potentially mess up your tags!
The upshot is that I have a system that automatically tags information correctly much of the time. It’s a time-saving feature that makes my information garden richer and more useful. But it comes at the expense of a tag collection that isn’t completely under my control.
Yesterday, I spent a few hours cleaning things up. I hadn’t “weeded” my collection in a while, and there were over 2,000 tags in the system. This included terms of varying degrees of granularity, minor variations of the same term (typos, etc.), versions with uppercase and lowercase characters, etc. It was a mess.
Early on, the system’s usefulness increases with every new tag. But eventually, you reach a point where every new tag makes the system less useful, since a large set of tags makes choosing the right tag for a new item more difficult. A huge set of tags also reduces the value of smart rules and groups, since there’s a long tail of tags in the system that only apply to one or two items.
Fortunately, DEVONthink provides great tools to merge and edit tags. In a couple of hours, I pared the list down to around 300. I can do better, and plan to edit the list further. But I’m already feeling better about the state of the system. The takeaway: I can’t let the tag collection grow out of control. Editing thousands of tags in one sitting takes a lot of time, so I must make a habit of “weeding” the garden periodically — perhaps weekly.
You may recognize tag management as a straight-up information architecture challenge. The difference is that here you’re not looking to manage a taxonomy to benefit other people. Instead, you’re specifying distinctions that will improve your garden’s ability to generate new connections. The “users” of this IA are 1) your future self and 2) your snazzy AI-powered assistant.
But that’s a different metaphor, and I prefer the image of the garden. Either way, this system is a powerful augmentation of my thinking abilities. But it comes with a cost: the need to proactively manage its information structures. It’s a small price to pay.