A transcript of a presentation I delivered at Rosenfeld Media’s DesignOps Summit 2024 conference.
Keeping large content repositories organized is an ongoing challenge. There’s always new stuff coming in, and taxonomies evolve over time. Resource-strapped teams seldom have opportunities to re-organize older content. As a result, users struggle to find the stuff they need when and where they need it.
When I say “large content repositories,” I mean two kinds of systems. The first kind exposes lots of content to end users. An example might be an online store with a large product catalog. The second kind are used by internal teams to aggregate knowledge. A common example are interview transcripts repositories used for research.
In both cases, people need to find information. But search isn’t enough: users must also understand what kind of information is in the system. To do this, the system must expose taxonomies — lists of categories — that give users a sense of what kind of stuff is in there.
We organize content in two phases. The first phase is when the system is first being built; it’s a blank slate. In many ways this is the easier scenario. The second phase is when the system has been operating for a while. There’s already a set of content items and categories, but changing conditions require that things evolve.
This entails not just adding and deleting content but also changing taxonomies and re-tagging content to reflect the new categories.
For example, consider what happens when a company releases a new product or enters a new market. The company updates their websites and support knowledge bases. They add new content, which needs to be tagged. Sometimes, they also create new taxonomy terms, which need to be applied to older content.
This is unglamorous work that often gets put off. Organizations prioritize building new products and features over keeping older content organized — especially now, when many are being cost-conscious. The result is content that isn’t as usable — or as useful — as it could be.
This is a task well-suited for AI. Large language models have powerful capabilities that can help teams keep content organized. Using LLMs for this leads to better UX and frees teams to focus on more valuable efforts.
I’ve been experimenting with using LLMs in this way. I will now share with you two use cases for organizing content at scale using AI. The first case entails re-tagging content with an existing taxonomy. The second covers defining a new taxonomy.
Use Case 1: Re-categorizing Content
Let’s start with the first use. As I mentioned earlier, this entails re-categorizing content with an existing taxonomy. This is desirable if either the content or the taxonomy has changed. As an experiment, I re-tagged content in my blog, jarango.com. I’ve published almost 1,200 posts there over the last two decades.
As with many repositories with a large back catalog, older content wasn’t getting enough visibility. I wanted to implement a “see also” feature so every post linked to related posts. The technique I used to surface these relationships entailed finding posts with at least two metadata tags in common.
But I had a few challenges:
- This required that all posts have a minimum of three tags. I’ve been disciplined about tagging recent posts, but older posts often only had one or two tags, which wasn’t enough.
- The taxonomy itself was outdated and inconsistent. It had evolved organically over twenty years, and included terms that were more meaningful to me than my users.
So I started by updating the taxonomy. That was easy enough. Making it clearer for my users also had the added advantage of making it easier for the LLM to use. The bigger challenge was re-tagging everything, which would require revisiting each post individually. I estimated this would take between 10-12 hours of mind-numbing work.
Doing it manually wasn’t worth it. So instead, I built a little Unix script that fed every post in my blog to GPT-4 with a prompt asking the LLM to assign it three tags from a predefined list.
This worked well, with a couple of caveats. The first is that even though my prompt insisted that the LLM abide by my taxonomy, GPT-4 introduced its own categories. The second is that I expected something like this to happen, because LLMs hallucinate.
So rather than have the script apply the new categories directly to the content files, I had it write them to an intermediary CSV file. There, I could review and tweak proposed changes before adding the metadata to the actual content files.

This slightly convoluted process allowed me to tap the power of the LLM while still giving me the final say on how my content is tagged. The process took about a third of the time it would’ve taken had I done it manually. But that included lots of learning on my end. Whenever I repeat the process in the future, the time savings will be even greater.
You can read more details about this use case – including the scripts and prompts — here.
Use Case 2: Developing New Categories
Let’s move on to the second use case, which covers using AI to define new content categories altogether. This is useful when working with a new system or when content has changed enough to merit new taxonomies.
The challenge here is different than in the first use case. Instead of focusing on individual content items, which is something LLMs can do easily, the object of interest here is the whole set of content items as a group.
In many cases, this set of content will be large enough to exceed the LLM’s context window. You can think of the context window as the LLM’s memory; the amount of stuff it can work with at any given time. It’s measured in tokens, which are tiny chunks of text.
Different language models have different context windows. GPT-4o’s context window is 128,000 tokens, which is equivalent to between 350-500 pages of text. Not bad, but again, might not be enough to process an entire repository. Also, there’s a cost and energy penalty to passing more content to the LLM.
There’s also the risk of analyzing content at the wrong level of granularity. If you pass the entire corpus — all of the content — to the LLM in one go and ask it to produce new categories, it will get derailed by all the details. So instead, you want to chunk content into more granular pieces before asking the LLM to find clusters of related content.
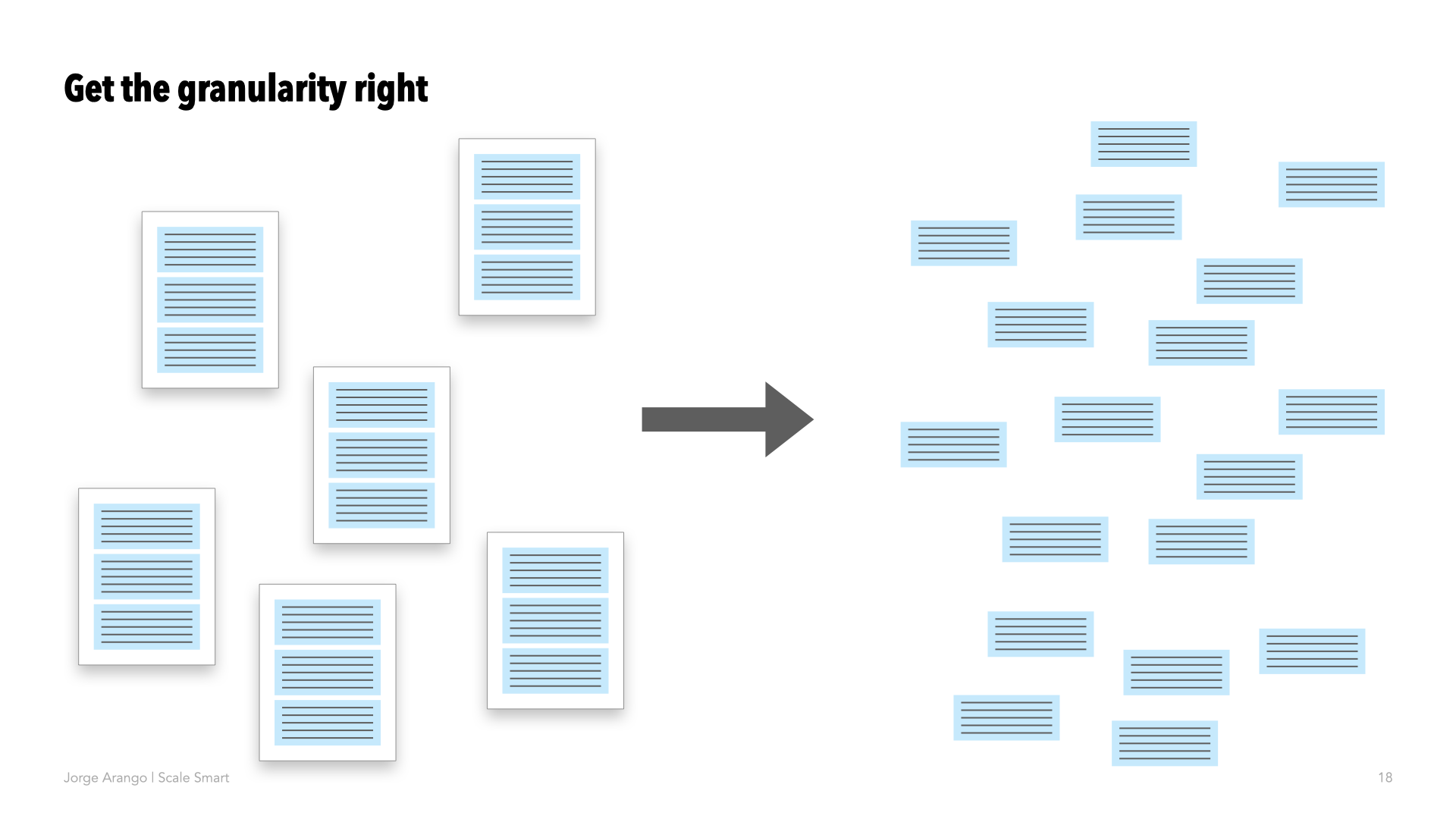
To do this, I’ve tried two approaches.
The first calls for using the LLM to build an embeddings database: basically, asking it to find statistical relationships between chunks of content from the repository and then using those embeddings to find possible clusters of related content.
I did an experiment using this approach on my podcast. At the end of 2023, I produced a “year in review” episode that highlighted a few common threads that emerged in interviews during the year.
This was possible because I had transcripts for each episode. Each interview transcript was already divided into chapters, which indicated a switch of topic in the conversation. I broke interview transcripts into separate files, one for each ‘chapter,’ and then used those to build an embeddings database. I then had GPT-4 suggest possible clusters of chapters.
This experiment was somewhat successful, although the final groupings required a lot of tweaking. That said, it did help me identify themes to highlight and conversation snippets to illustrate them.
I had done this process manually in previous years, and using the LLM saved me about half the time. The next time I do it, I expect to be even faster. That said, I may not do it like this the next time.
That’s because I’m now exploring another approach, which I’m finding more successful. Rather than building an embeddings database and then finding clusters, I’m using a technique called RAG, or retrieval augmented generation.
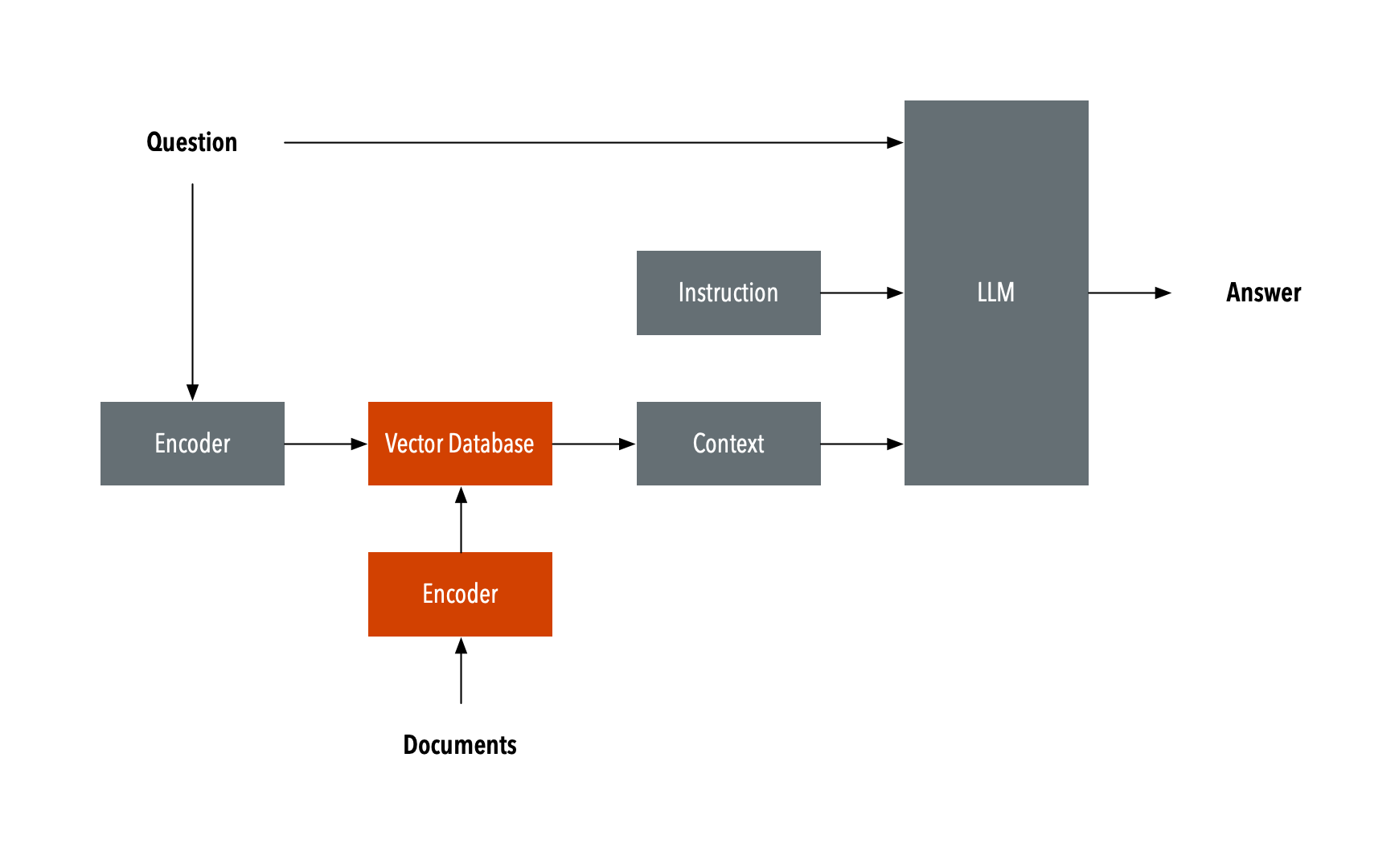
Diagram after https://commons.wikimedia.org/wiki/File:RAG_schema.svg
{kind=link}
To oversimplify a bit, RAG combines the power of LLMs with search. When the user issues prompt, the AI searches through the repository to inject the right content into the prompt. This improves results by focusing on the specific content the user has asked about, which cuts down on hallucinations.
Basic RAG does this using plain text. But the variation I’m exploring, which is called graph RAG, uses the LLM to build a knowledge graph of the corpus beforehand. It then uses this knowledge graph to identify the right content to inject into the prompt.
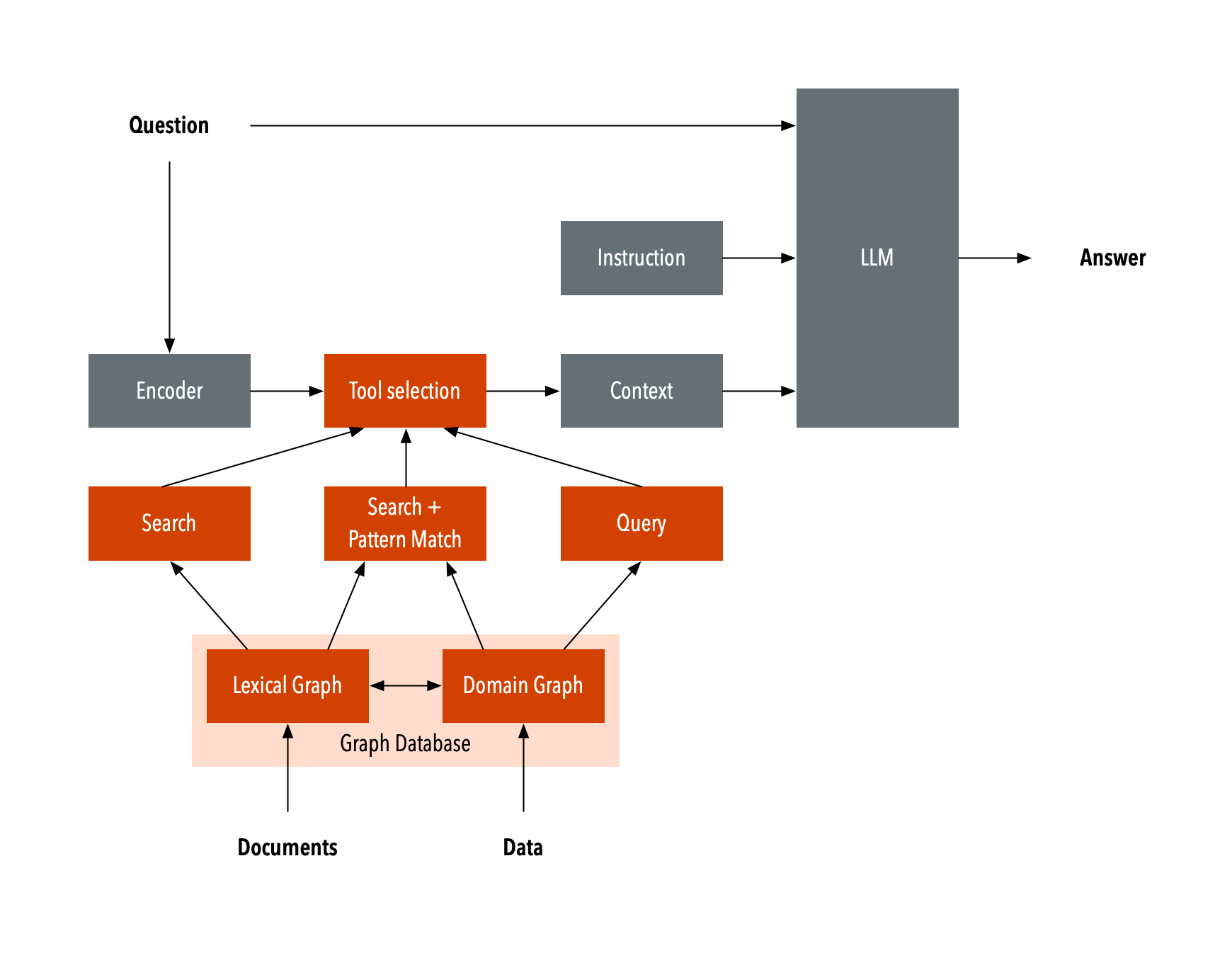
Diagram after https://commons.wikimedia.org/wiki/File:GraphRAG.svg
{kind=link}
Because the knowledge graph encodes semantic relationships between terms, the results are more precise than when using plain RAG. Graph RAG also makes it possible to specify the desired level of granularity when interacting with the corpus.
For example, I can issue prompts about specific content items or ‘global’ prompts at the level of the whole corpus, depending on the task at hand.
I’m currently using this approach to reorganize a client website. Using graph RAG, I’ve summarized the entire site, learned about the content, and even had the LLM help me draft new taxonomies. As a bonus, I’ve forever banished lorem ipsum text from my wireframes, since I can now easily generate realistic copy based on the website content itself.
You can read more about this use case here.
Overall Lessons Learned
Which is to say, LLMs have made my work faster and more efficient. But they’ve also opened up new ways for me to work with content at scale.
These systems hold tremendous potential for organizing large content repositories. They’ve already saved me lots of time, and they open other possibilities for making the work better and faster. LLMs have clear value in these use cases.
But note I’m not using these things to generate ‘live’ experiences on-the-fly. In both use cases, I used the AI to augment my work as an information architect. My clients and I have the final call on what goes into production. The key is augmenting humans, not replacing them.
Working with AI requires different workflows. These tools have amazing capabilities, but they don’t do any of this automatically, despite what marketing hype would have you believe. LLMs have real limitations that you can only discover by actually using them.
Learning to augment your IA work with AI requires rolling up your sleeves and using the tools. Fortunately, they are easily accessible. There are also lots of ways to learn about this stuff.
I’ve created a page on my website that aggregates resources related to AI. There, you will find deeper descriptions and source code for most of the use cases I’ve shared today. If you do experiment with this stuff, please reach out. I’d love to learn how it goes for you. Good luck!