
I recently wrote about how I used GPT-4 to implement a “see also” feature on my blog. I undertook that project for two reasons: to give older content on my site more exposure, and to give me firsthand experience with automating aspects of my work using AI.
The experiment succeeded on both counts. The “see also” feature works as expected. Re-categorizing all 1,163 posts on my site took only a fifth of the time it would’ve taken me to do it manually. A big win!
My previous post explained the approach in detail. Here, I’ll generalize what I learned into a model that can be used in other scenarios. I’ll wrap up with lessons gleaned from the process.
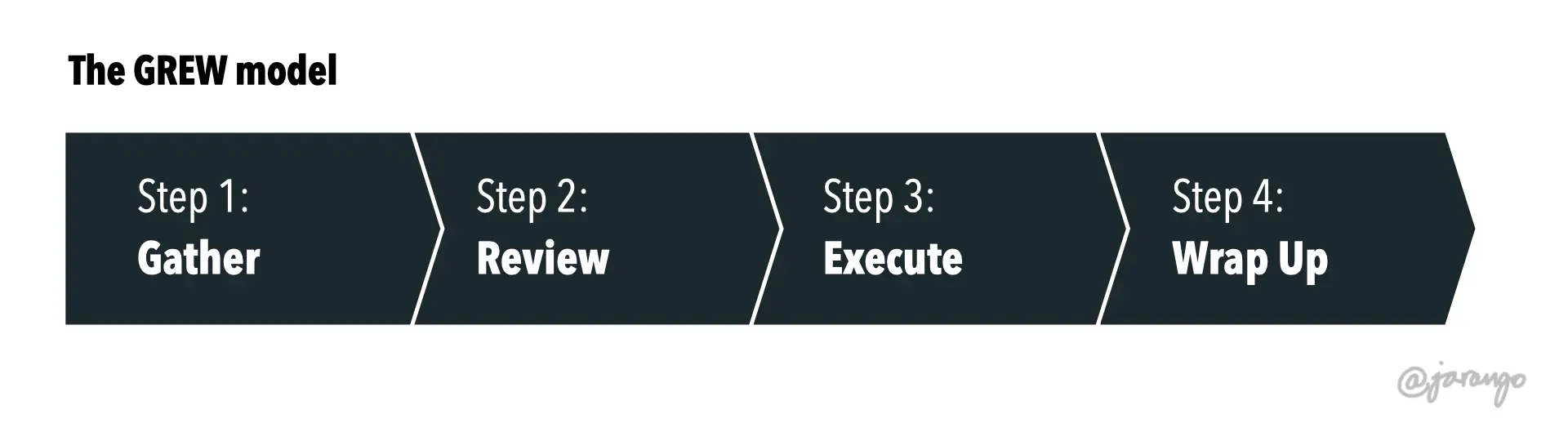
I’ve synthesized the process into the four-step GREW model:
- Gather: prepare the materials to be modified
- Review: do a test run of proposed changes in a safe, reversible state
- Execute: make the proposed changes
- Wrap Up: tie loose ends
Let’s look at each step in more detail.
Step 1: Gather
This is mise en place: preparing the data you’ll process. In my case, GPT-4 ‘read’ each blog post to tag it. So the data consisted of two things:
- My site’s blog posts
- The list of tags that describe those blog posts
If I were doing this for a client who uses WordPress, Drupal, or some other CMS, I’d have to download copies of their content. I could do this by spidering their sites, downloading everthing in their sitemap.xml files, or asking for dumps from the CMS itself. But my blog is built using a static site generator, so all posts are already stored in my computer as plain text Markdown files.
The list of tags required more work. As I mentioned in my previous post, I had to eliminate idiosyncratic acronyms from the taxonomy, such as TAOI. This term was meaningless to anybody but me; I could expect GPT-4 to not know what to do with it. Of course, I could teach the LLM what this means via prompt engineering. But if it’s confusing GPT-4, it’s likely confusing my users as well. So I removed it before starting.
In my “see also” scenario, the tags taxonomy is a simple text list. I intentionally kept it simple so it’d be easier to pass in a prompt. I could imagine a more elaborate version of this step that involves a more complex tag structure. This would entail more sophisticated prompt engineering; totally doable.
With the content and terms in place, we’re ready for LLM to do its thing.
Step 2: Review
This is where AI goes to work on the data. But the key is to not have it modify the data directly. You want oversight before the AI changes your stuff. The reasons why are worth unpacking.
Generative AI is a new kind of computation. Previous algorithms were deterministic: given the same states and inputs, you could expect precisely predictable outputs. In contrast, genAI is probabilistic: you can’t predict outputs, only probabilities.
What this boils down to: you can’t fully control genAI. At best, you can ‘work with it’: try something, see what it does, and tweak the results. That’s not bad; we’ve worked with other probabilistic systems. (E.g., try assigning a complex task to an intern.) People are being thrown for a loop because computers have never done this.
You work with probabilistic systems differently than deterministic systems. For one thing, you must check their work. You wouldn’t send the intern’s additions to the quarterly report to the CEO without reading and tweaking them. Same goes for LLMs.
I could’ve easily set up my process to have GPT-4 modify each Markdown file as it ‘read’ it. But that would’ve been irresponsible. What if it added something I didn’t want? Again, it’s a probabilistic system; I can’t expect it to do exactly what I expect. (That’s what makes it so powerful!)
So instead, I set it up to save proposed file-tag relationships to a CSV file where I could review proposed changes. When perusing the CSV file, I found several tags where the LLM didn’t follow my prompt precisely. I tweaked them before moving on to step three.
This approach worked well; I’ll likely do the same thing when doing this for clients, perhaps varying the exact form of the review file. (Since LLM outputs plain text, this intermediary step could take many different forms.)
Step 3: Execute
This step entails implementing the changes proposed by the LLM. In my case, there was no AI involved in this step at all, just plain old shell scripting. (The epitome of deterministic programming!) You can read about my approach in more detail (including source code) in the previous post.
This is the step that would likely change most if I were doing this for a client. In my case, I had to find ways of modifying plain text Markdown files in place. That works well when using static site generators, but not much else.
If a client’s site uses a CMS like Drupal or WordPress, I’d look to leverage those system’s APIs to re-tag content programmatically. You obviously don’t want to automatically change any production system at scale in this way, so this needs to happen on a development environment with a path to production.
Step 4: Wrap Up
You’re not done when the changes are implemented. You must review the results on the development system before pushing to production. As I noted in the previous post, I discovered several unexpected additions to the taxonomy at this step in the process. Some changes I accepted into the taxonomy, others I rejected.
How you visualize changes depends on the CMS. In my case, I could see the new taxonomy in my blog’s Archive page. Systems like WordPress have built-in taxonomy editors that let you peruse and modify these vocabularies more conveniently. I’d expect to spend time during the project cleaning things up before committing to production.
Lessons Learned
Although I haven’t tried it with a client yet (please get in touch if you’d like to have a go!), I expect this model has legs. It leverages the power of AI to expedite the work without sacrificing human oversight. But beyond these benefits, working on this project has taught me three important lessons:
-
Think outside the (chat)box. Many people equate AI with chatbots. This is understandable; ChatGPT was a marketing masterstroke. But using generative models via their APIs opens them up to integrations with other tools and workstreams. In my case, that meant working with files on my computer, but it could as easily be any other systems that also expose APIs.
-
Make it easy for the AI (and people will benefit too.) Getting the content and taxonomy in place was essential. And making the terms in the taxonomy more understandable was critical. Over the time I’ve worked with GPT-4, I’ve come to see it as having somewhat middlebrow ‘tastes’ by default. What I mean by this is that, absent specialized prompting, the system gives rather milquetoast responses. As such, it can be a good proxy for ‘average’ users; if GPT-4 doesn’t know what to do with a term like TAOI, many people won’t either.
-
Probabilistic computing is weird! The IA will do its own thing. Depending on how much say you want in the final results, you must introduce steps in the process where you check the work before moving on. In this model, the Review and Wrap Up steps provide those opportunities at different stages in the process.
The more I work with these systems, the more I’m convinced they represent a major shift in how we do knowledge work. Writing on X, Dare Obasanjo posed the following question:
I sometimes wonder if LLMs are this generation’s self driving cars? A decade ago self driving cars were so promising it was assumed they were 90% of the way to being ubiquitous. But now it looks like the last 10% of the work is taking 90% of the time.
LLMs work well 90% of the time. The question is how hard will it be to address that last 10%?
I assume that by “last 10%,” Obasanjo means something like AGI. If so, this analogy doesn’t stand. Self-driving cars won’t be useful until that last 10% is overcome. But even as unpredictable as they are, LLMs are already quite useful. Even if that last 10% is never settled, there are plenty of workflows that can be vastly improved by using generative models with human oversight. The GREW model offers an approach for doing so.